



بهروزنامه — شماره ۲۸
هوش مصنوعی و خوندن افکار شما

سلام! خوبید؟
یه پنجشنبه دیگه با یه بهروزنامه دیگه. مرسی از همه اونایی که میخونن و با به اشتراک گذاشتن اونها از من و بهروزنامه حمایت میکنن. بدون کش دادن اولیه، میریم سر اصل مطلب.
مثل همیشه، نظری، انتقادی، پیشنهادی چیزی داشتید یا کامنت بذارید، یا همین ایمیل رو ریپلای کنید؛ یا اینجاها میتونید پیدام کنید:
اینستاگرام | توییتر | بلواسکای | کلابهاوس

گوگل پشتیبانی از Passkey (بجای پسورد) رو برای ورود به اکانتهاش اضافه کرد (منبع).
راجع به «مرگ پسورد» پارسال نوشتم؛ هم در بهروزنامه، هم در توییتر.
اپل و گوگل یه بسته پیشنهادی فنی ارائه کردن برای مبارزه با ردیابی موقعیت ناخواسته از طریق بلوتوث (مثل AirTag های اپل)؛ و از شرکتهای دیگه نظر خواستن (منبع)
گوگل قصد داره نماد قفل روی نوار آدرس کروم رو که برای نشون دادن «امنیت وب سایت» (در واقع نشان دادن HTTPS) هست رو از کروم نسخه ۱۱۷ به بعد تغییر بده؛ چرا؟ چون تقریبا همه سایتهای فیشینگ هم از HTTPS استفاده میکنن! (منبع)
تیک آبی وریفاید؛ این بار برای دامنهها و فرستندگان ایمیل در جیمیل (منبع)
کمپانی IBM اعلام کرده که سرعت استخدام در بسیاری از بخشها رو خیلی کم و متوقف میکنه؛ بیش از ۲۶ هزار کارمندی که ۳۰ درصد اونها در ۵ سال آینده «به راحتی» میتونن با هوش مصنوعی جایگزین بشن تحت تاثیر این تصمیم قرار میگیرند (منبع)
سامسونگ استفاده کارمندانش از ابزارهای هوش مصنوعی مثل ChatGPT و Google Bard رو روی دستگاههای شرکت ممنوع کرد. دلیل: نگرانی از افشای اطلاعات خصوصی و محرمانه توسط کارمندان (منبع)
توییتر دسترسی رایگان به API خودش رو برای سرویسهای وریفاید دولتی یا عمومی بازمیگرداند؛ سرویسهایی که هشدارهای مربوط به آب و هوا، حمل و نقل و نوتیفیکیشنهای اضطراری پست میکنن (منبع)
مدیر محصول سابق OpenSea که متهم به insider trading شده بود، توسط هیئت منصفه مجرم شناخته شد. (منبع)
راجع به این در بهروزنامه ۱۴ توضیح داده بودم.
ایلان ماسک به یکی از خبرنگارهای NPR ایمیل زده: «حالا NPR میخواد بازم توییت کنه یا یوزرنیم NPR رو بدیم یه کمپانی دیگه؟» (منبع)
نابودی Chegg (یک کمپانی تولید محتوای کمک آموزشی و حل تمرین و مشق) توسط هوش مصنوعی (اینجا ChatGPT) در یک نمودار (منبع)
نتفلیکس تقریبا یک میلیون مشترک در اسپانیا از دست داد بعد از گیر دادن شدید به کسانی که پسوردهاشون رو با بقیه به اشتراک میذارن؛ نتفلیکس میگه این افت موقتیه و مشترکین جدید جاشون رو میگیرن (منبع)
رشد ۸/۸ درصدی بازار تبلیغات در بریتانیا در سال ۲۰۲۲ و رسیدن ارزش اون به ۳۴/۸ میلیارد پوند (۴۳/۷ میلیارد دلار) (منبع)

هوش مصنوعی و خوندن افکار شما
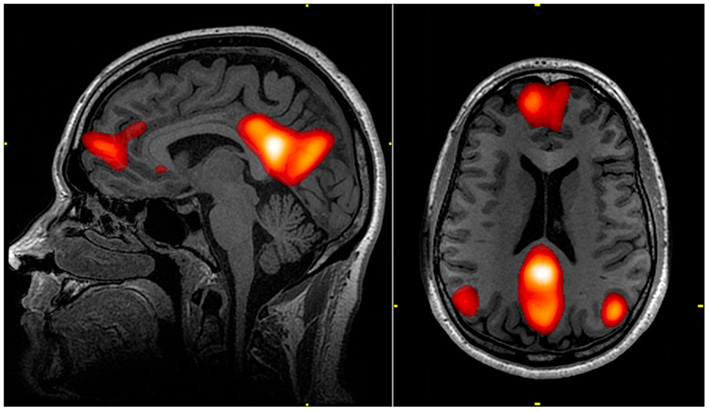
هوش مصنوعی مولد (تولید کننده) یا Generative AI که بین عموم با ChatGPT شدیدا داغ شده، یه حرکت فوق العاده و جدید زده که بیشتر خبریه تا تحلیلی، ولی خب در ادامه بخش تحلیلی هفته پیش، اینجا میخوام یه ذره راجع بهش توضیح بدم.
اتفاقی که چشم اندازهای جدیدی رو برای بازیابی گفتار در افرادی که به دلیل سکته مغزی یا بیماریهای نورون حرکتی قادر به صحبت نیستن ایجاد میکنه.
دانشمندان یه رمزگشای (decoder) مبتنی بر هوش مصنوعی ساختن که میتونه فعالیتهای مغز رو به یک جریان متنی پیوسته ترجمه کنه! این اولین بار هستش که این دستگاه میتونه افکار یک شخص رو به صورت غیر تهاجمی (non-invaisive) بخونه (بدون اینکه دستگاهی وارد بدن شخص بشه).
این رمزگشا (دیکودر) میتونه افکار شخص رو هنگام شنیدن یا تصور یک داستان در سکوت، از طریق دادههای اسکن fMRI یا Functional Magnetic Resonance Imaging با دقت عجیبی بازسازی کنه. سیستمهای رمزگشای قبلی برای کار کردن نیاز به کاشت ایمپلنت (implant) در بدن بیمار از طریق جراحی داشتن. از همین رو، این اتفاق یه پیشرفت خیلی بزرگ در این زمینه است.
دکتر الکساندر هوث (Alexander Huth)، عصب شناسی که رهبری این پژوهش در دانشگاه تگزاس در آستین رو به عهده داشت گفته: «ما تقریبا شوکه شدیم که این به این خوبی کار میکنه. من ۱۵ ساله که دارم روی این موضوع کار میکنم… برای همین وقتی بالاخره جواب داد، برام خیلی تکان دهنده و هیجان انگیز بود.»
این دستاورد بر یکی از مهمترین محدودیتهای fMRI غلبه کرده. با اینکه fMRI میتونه فعالیت مغز رو در یک نقطه با وضوح بالا نشون بده، اما یک تاخیر ذاتی در سیستم وجود داره که باعث میشه ردیابی فعالیتها در real-time غیرممکن بشه.
این تاخیر به این دلیله که اسکنرهای fMRI جریان خون در پاسخ به فعالیت مغز رو اندازه میگیرن که در حدود ۱۰ ثانیه به اوج میرسن و بعد به سطح اولیه بازمیگردن. برای همین، حتی قویترین اسکنرها هم نمیتونن این رو بهبود ببخشن.
این محدودیت، توانایی تفسیر فعالیت مغز در پاسخ به گفتار طبیعی رو با مشکل مواجه کرده، چون یه «مخلوطی از اطلاعات» رو در چند ثانیه یهو پخش میکنه.
اما با این حال، ظهور مدلهای زبانی بزرگ (LLM)، مثل همین ChatGPT از OpenAI، راه جدیدی رو برای این حل این مشکل ایجاد کرده. این مدلها میتونن محتوای معنایی گفتار رو به صورت عددی نشون بدن و به دانشمندان اجازه بدن که الگوهای فعالیتهای عصبی رو با الگوهای معنایی مقایسه کنن؛ به جای اینکه بخوان الگوهای عصبی رو با کلمه کلمه محتوا مطابقت بدن.
یه جورایی مثل ترجمه مفهومی به جای ترجمه کلمه به کلمه
البته فرآیند یادگیری هوش مصنوعی در این پژوهش بسیار فشرده بوده: سه داوطلب، هر کدوم ۱۶ ساعت در یک اسکنر دراز کشیدن و پادکست گوش دادن. این دیکودر، برای تطبیق فعالیتهای مغز با معنا، از مدل GPT-1 استفاده کرده؛ از اجداد ChatGPT (که الان داره از GPT-4 استفاده میکنه!)
بعدش، همون داوطلبان در حال گوش دادن یا تصور کردن یک داستان جدید اسکن شدن و از این دیکودر برای تولید متن از فعالیت مغز اونها استفاده شده. تقریبا نیمی از مواقع، متن تقریبا با معانی کلمات مورد نظر مطابقت داشت؛ و گاهی هم دقیقا متن مطابق کلمات مورد نظر بود.
دکتر هوث گفت: «سیستم ما در سطح ایدهها و معنا کار میکند. برای همینه که چیزی که از این سیستم میگیریم، دقیقا کلمات مورد نظر نیستن، اما اصل مفهوم رو منتقل میکنن.»
به عنوان مثال، وقتی برای یکی از داوطلبان جمله اصلی این بود که «من هنوز گواهینامه رانندگی ندارم»، دیکودر اون رو به این صورت ترجمه کرده: «او هنوز شروع به یادگیری رانندگی نکرده است». در مورد دیگه، وقتی عبارت اصلی «نمیدونستم فریاد بزنم، گریه کنم یا فرار کنم؛ بجاش گفتم: منو تنهام بذار!» بود، دیکودر اون رو «شروع به جیغ زدن و گریه کرد و بعد گفت: بهت گفتم منو تنها بذار!» ترجمه کرد.
این مقاله که در nature neuroscience چاپ شده، گزارش داده که از شرکت کنندهها خواسته شده که هنگامی که در اسکنر هستن، چهار ویدیو صامت (بی صدا) ببینن و بعد دیکودر تونسته، از طریق فعالیتهای مغز اونها، توصیف دقیقی از برخی از محتوای اون فیلمها ارائه بده.
دکتر هوث گفته به عنوان یک روش غیرتهاجمی (non-invasive method)، این یک گام بلند رو به جلوست، مخصوصا در مقایسه با کارهایی که قبلا انجام شده که در بهترین حالت فقط شامل کلمات یا جملات کوتاه بودن.
به طرز جالبی، دیکودر تو تشخیص بعضی چیزها هم خیلی ضعیف عمل کرده؛ مثل اول شخص یا سوم شخص بودن یا مثل جنیست ضمیرها (he و she و اینا) و هوث گفته: ما هنوز نمیدونیم دلیلش چیه.
علاوه بر اون، وقتی دیکودر برای کسی شخصی سازی میشد و روی شخص دیگه تست میشد، محتوایی که تولید میکرد نامفهوم بود. همچنین کسانی که دیکودر براشون شخصی سازی شده بود میتونستن با فکر کردن به حیوانات یا یواشکی تصور کردن یه داستان دیگه، سیستم رو گول بزنن.
پروفسور تیم بهرنز (Tim Behrens)، متخصص علوم اعصاب محاسباتی در دانشگاه آکسفورد که در این پژوهش دخالتی نداشته اون رو «از لحاظ فنی بسیار چشمگیر» توصیف کرده و گفته این پروژه امکان تحقیق و آزمایش در زمینه بررسی رویاها (خواب دیدن) و چگونگی پرورش ایدههای جدید بسیار کمک میکنه. وی اشاره کرد که «این مدلهای مولد به شما امکان میدن سطح جدیدی از آنچه در مغز وجود داره ببینید. این به این معنی است که شما میتونید چیزهایی رو از عمق fMRI بخونید [که قبلا نمیتونستید].»
پروفسور شنیجی نیشیموتو (Shinji Nishimoto) از دانشگاه اوزاکا ژاپن که در بازسازی تصاویر از طریق فعالیتهای مغز پیشگامه، این مقاله رو «پیشرفتی قابل توجه» توصیف کرده و گفته: «این مقاله نشان داد که مغز اطلاعات زبانی پیوسته در طول ادراک و تخیل رو به شکل سازگار باهم پردازش میکند. این یک یافته پیش پا افتاده نیست و میتواند مبنایی برای توسعه رابط (interface) بین مغز و کامپیوتر باشد.»
تیمی که این پژوهش رو انجام دادن امیدوارن که بتونن این روش رو برای سایر سیستمهای تصویربرداری از مغز مثل fNIRS یا functional near-infrared spectroscopy استفاده کنن.
منبع: گاردین
تازه فکر کنید اینا با GPT-1 این کارو انجام دادن… و ما الان به GPT-4 دسترسی داریم… تصور این که این کار با مثلا GPT-10 چطوری میشه واقعا عجیب غریبه!

تحلیل هفته پیش
خب، طبق معمول، من در راستای بهتر شدن بهروزنامه و خودم، میخوام ببینم بازخورد بخش تحلیلی هفته پیش چطور بود. چرا؟ چون هم طولانی بود، هم به نظرم بحث مهمی بود که خب به همین دلیل این هفته هم یه جورایی ادامه دادمش…
مرسی که با جواب دادن به نظرسنجی زیر (و شاید کامنت گذاشتن) به بهتر شدن من و این خبرنامه کمک میکنید. راستش رو بگید 😅 خب؟
این چه تاثیری داره؟
تاثیرش اینه که به من کمک میکنه لااقل بدونم این وقتی که دارم برای تولید بهروزنامه میکنم، نتیجه هم داره… اگه نتیجه اینجوری باشه که بازخورد یه محتوایی که ۳ ساعت زمان میبره، خیلی بهتر از بازخورد یه محتواییه که ۱۲ ساعت زمان میبره، خب من سعی میکنم از اون ۳ ساعتهها بیشتر تولید کنم! هم وقتم کمتر صرف میشه، هم مفیدتره.
در ضمن، شاید کمک کرد بهروزنامه نسخه مکمل صوتی یا تصویری پیدا کنه… همه چی بستگی به خودتون داره 😁
علاوه بر اون، میخواستم قابلیت نظرسنجی ساب استک رو هم تست کنم؛ هرچند جدید نیست.
ولی میدونید چی جدیده؟ مدل صفحه اول بهروزنامه. خودتون ببینید.

RoverX - یه اپ دیگه برای اینکه مانیتور کردن پورتفولیو NFTهات.
طراح مایکروسافت رو هم چک کنید… احساس میکنم رقیب سختی برای Canva باشه!
فونت آرا - افزونهای رایگان و متنباز برای بهبود فونت فارسی در تمام وب (کاری از مصطفی الهیاری که موسس Zil.ink هم هست).
حالا چرا فونت آرا؟ از اونجایی که ساب استک متاسفانه فونت فارسی درست حسابی نداره، اگه بهروزنامه رو روی مرورگر دسکتاپ بخونید، با استفاده از فونت آرا، میتونید اون رو با فونت بهتر بخونید. مثلا این شکلی:
بهروزنامه - با فونت آرا روی دسکتاپ



این توییت دیجیپی ریپلایها و کوتهای باحالی داره.
توجه شما رو جلب میکنم به ثانیه ۹ این ویدیو.
سنی که کسب و کارهاشون رو استارت زدن… (یه لیست که احتمالا توش اسم آشنا زیاد میبینید)

رفراندوم از اون کلماتیه که زیاد میشنویمش (مخصوصا در ماههای اخیر)، ولی چقدر واقعا راجع بهش میدونیم؟ توی این ویدیو، علی حجوانی خیلی مختصر و مفید راجع به رفراندوم برامون توضیح میده.
این کانال یوتیوب ژورنال، همونطوری که احتمالا خودتون میدونید، یه [خبرنامه ایمیلی] ساب استک هم داره که اینجا میتونید ببینید و بخونید و عضوش بشید:
شماره ۲۸ بهروزنامه هم تموم شد. برعکس قبلی، خیلی طولانی نبود.
ولی یه نکته جذاب داشت… لااقل واسه خودم! اونم این بود که یکی دوتا رفرنس دادم به شمارههای پارسال بهروزنامه… اینکه موضوعاتی که الان مطرح هستش رو قبلا راجع بهش حرف زده بودم به نظرم نشون میده که یکپارچگی لازم رو از لحاظ موضوعی داریم؛ و این خوبه.
دوباره هم یادآوری میکنم که اگر چیزی پیدا کردید یا تولید کردید (محتوا یا محصول یا هرچی) که فکر میکنید برای مخاطبین بهروزنامه مفیده، بهم پیام بدید. (راهش رو خودتون پیدا میکنید.)
کنجکاو بمونید. تا شماره بعد؛
بهروز
بخش تحلیلی، معرفی طراح مایکروسافت و بخصوص از گوشه های اینترنت (😂) عالی بود
ممنون از لطفت بهروز جان. باعث افتخاره که مورد توجهت بود. ممنونم.